图论
生活不就是一张图吗?
一、定义#
图(Graph)用于表示物件与物件之间的关系,是图论的基本研究对象。一张图由一些小圆点(称为顶点或结点)和连结这些圆点的直线或曲线(称为边)组成。
一个图 $G$ 是一个二元组,即序偶 $\langle V,E\rangle$ ,或记作 $G= \langle V,E\rangle$ ,其中 $V$ 是有限非空集合,称为 $G$ 的顶点集, $V$ 中的元素称为顶点或结点; $E$ 称为 $G$ 的边的集合, $\forall e_i \in E$ ,都有 $V$ 中的结点与之对应,称 $e_i$ 为 $G$ 的边。
简单来说,就是图 $G$ 就是一个结点的集合 $V$ 和边的集合 $E$ ,其中任意一条边都可以表示为两个结点之间的关系。若 $e_i\in E$ 表示为 $\langle u,v\rangle$ ,则有 $u\in V , v\in V$ 。
1.1 基本概念#
无向图:每条边都是无向边的图。
有向图:每条边都是有向边的图。
有权图:每条边具有一定的权重(weight),通常是一个数字。
无权图:每条边均没有权重,也可以理解为权为 1。
连通图:所有的点都有路径相连。
非连通图:存在某两个点没有路径相连。
邻接:关联于同一条边的两个点 $u$ 和 $v$ 称为邻接的;关联于同一个点的两条边 $e_1$ 和 $e_2$ 是邻接的(或相邻的)。
1.2 结点的度数#
设图 $G= \langle V,E\rangle$ 为一个有向图, $v\in V$ ,关联于结点 $v$ 的 边 的条数,称为点 $v$ 的度数,记作 $\deg(v)$ 。
注意:一个自环为它的端点增加 2 度。
当图 $G= \langle V,E\rangle$ 为一个有向图, $v\in V$ ,称以 $v$ 作为始点的边数之和称为结点 $v$ 的出度,记为 $\deg^{+} (v)$ 。将以 $v$ 作为终点的边数之和称为结点 $v$ 的入度,记为 $\deg^{-} (v)$ 。称以 $v$ 作为端点的边数之和为结点 $v$ 的度数或度,记为 $\deg(v)$ 。
显然, $\forall v\in V,\deg(v)=deg^{+} (v)+\deg^{-} (v)$ 。
二、图的存储#
以下图作为例子。
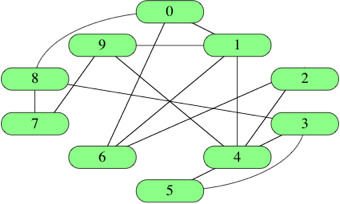
2.1 直接存边#
建立一个数组,数组里每个元素是图的一条边。
这样做有个缺点,每次想要知道两个点之间是否有连边(或者说一条边是否存在),都需要在数组里进行一番查找。而且如果没有对边事先排序的话,就不能使用二分查找的方法( $O(\log n)$ ),而是每次只能按顺序找( $O(n)$ ),成本较高。
什么时候会用到这个方法呢?最简单的一个例子是使用 Kruskal 算法求最小生成树的时候。
[ [0,1], [0,6], [0,8], [1,4], [1,6], [1,9], [2,4], [2,6], [3,4], [3,5],
[3,8], [4,5], [4,9], [7,8], [7,9] ]
2.2 邻接矩阵#
邻接矩阵的英文名是 adjacency matrix。它的形式是 bool adj[n][n] ,这里面 $n$ 是节点个数, $adj[i][j]$ 表示 $i$ 和 $j$ 之间是否有边。
如果边有权值,也可以直接用 int adj[n][n] ,直接把边权存进去。
它的优点是可以在 $O(1)$ 时间内得到一条边是否存在,缺点是需要占用 $O(n^2)$ 的空间。对于一个稀疏的图(边相对于点数的平方比较少)来说,用邻接矩阵来存的话,成本偏高。

2.3 邻接表#
邻接表英文名是 adjacency list。它的形式是 vector adj[n] ,用 adj[i] 存以 $i$ 为起点的边。
用 vector 无法科学地删除,所以常用 list 实现。
它的特点是可以用来按顺序访问一个结点的出边(或者入边)。
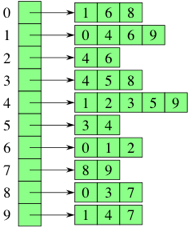
[ [1, 6, 8],
[0, 4, 6, 9],
[4, 6],
[4, 5, 8],
[1, 2, 3, 5, 9],
[3, 4],
[0, 1, 2],
[8, 9],
[0, 3, 7],
[1, 4, 7] ]
三、图的遍历#
图的遍历问题分为四类:
- 遍历完所有的边而不能有重复,即所谓“欧拉路径问题”(又名一笔画问题 );
- 遍历完所有的顶点而没有重复,即所谓“哈密顿路径问题 ”。
- 遍历完所有的边而可以有重复,即所谓“中国邮递员问题 ”;
- 遍历完所有的顶点而可以重复,即所谓“旅行推销员问题 ”。
对于第一和第三类问题已经得到了完满的解决,而第二和第四类问题则只得到了部分解决。
第一类问题就是研究所谓的欧拉图 的性质,而第二类问题则是研究所谓的哈密顿图 的性质。
图的遍历方法有深度优先搜索法和广度(宽度)优先搜索法。以下图为例。
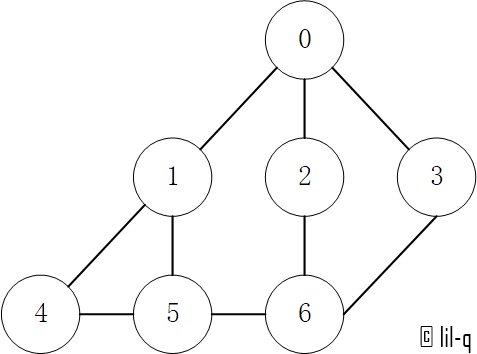
建立邻接表:
adjacencylists = [[1, 2, 3],
[0, 4, 5],
[0, 6],
[0, 6],
[1, 5],
[1, 4, 6],
[2, 3, 5]]
3.1 深度优先搜索#
深度优先搜索算法(Depth-First-Search,DFS)是一种用于遍历或搜索树或图的算法。沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点 v 的所在边都己被探寻过,搜索将回溯到发现节点 v 的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。属于盲目搜索。
3.2 广度优先搜索#
广度优先搜索算法(Breadth-First-Search,BFS),又译作宽度优先搜索,或横向优先搜索,是一种图形搜索算法。简单的说,BFS 是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。广度优先搜索的实现一般采用 open-closed 表。
Python的简易实现
# 设置总节点数
num_vertexs = 7
# 建立邻接表
adjacencylists = [[1, 2, 3],
[0, 4, 5],
[0, 6],
[0, 6],
[1, 5],
[1, 4, 6],
[2, 3, 5]]
class graph:
def __init__(self, num_vertexs, adjacencylists):
self.num_vertexs = num_vertexs
self.adjacencylists = adjacencylists
def dfs(self, start):
# 记录节点是否已经访问
visited = [False] * self.num_vertexs
res = []
def helper(v):
if visited[v]:
return
visited[v] = True
res.append(v)
for i in self.adjacencylists[v]:
helper(i)
helper(start)
return res
def bfs(self, start):
visited = [False] * self.num_vertexs
visited[start] = True
res = [start,]
queue = [start,]
while queue:
cur = queue.pop(0)
for i in self.adjacencylists[cur]:
if not visited[i]:
queue.append(i)
visited[i] = True
res.append(i)
return res
if __name__ == '__main__':
# 实例化
graph = graph(num_vertexs, adjacencylists)
t1 = graph.dfs(0)
print("深度优先搜索:", t1)
t2 = graph.bfs(0)
print("广度优先搜索:", t2)
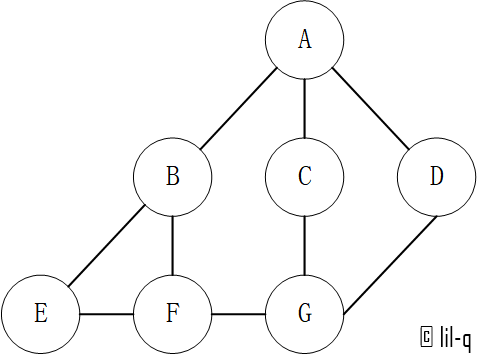
注意:这里用 index 表示节点名称,最后还需要映射出结果(假设0, 1, 2, 3…分别对应A, B, C, D, … 下文会使用字典来实现邻接表,这样就不需要这一步了):
vertexs = ["A", "B", "C", "D", "E", "F", "G"]
t3 = list(map(lambda x: vertexs[x], t1))
print("深度优先搜索:", t3)
t4 = list(map(lambda x: vertexs[x], t2))
print("广度优先搜索:", t4)
输出:
深度优先搜索: [0, 1, 4, 5, 6, 2, 3]
广度优先搜索: [0, 1, 2, 3, 4, 5, 6]
深度优先搜索: ['A', 'B', 'E', 'F', 'G', 'C', 'D']
广度优先搜索: ['A', 'B', 'C', 'D', 'E', 'F', 'G']
四、最短路径算法#
4.1 Dijkstra算法#
特点
Dijkstra 算法使用了广度优先搜索解决赋权有向图或者无向图的单源最短路径问题,算法最终得到一个最短路径树。该算法常用于路由算法或者作为其他图算法的一个子模块。Dijkstra 算法属于单源算法,即只能求出某点到其它点最短距离,并不能得出任意两点之间的最短距离,只能用权值为正数的图,存在负数时可能回陷入死循环。
流程
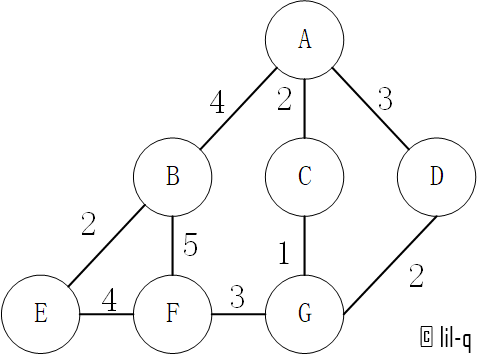
Dijkstra 算法采用的是一种贪心的策略,声明一个数组 distances 来保存源点到各个顶点的最短距离和一个保存已经找到了最短路径的顶点的集合:nodes。以下图为例,假设求A点到其他点的距离。
-
初始化 distances,原点 s 的路径权重被赋为 0 (dis[s] = 0)。把到其他顶点的路径长度设为无穷大。
distances = {'A': 0, 'B': inf, 'C': inf, 'D': inf, 'E': inf, 'F': inf, 'G': inf} -
初始 nodes,理论上集合 nodes 只有顶点 s。这里创建了其他节点是方便之后的进堆操作,不用再考虑节点是否存在两种情况。
nodes = [[0, 'A'], [inf, 'B'], [inf, 'C'], [inf, 'D'], [inf, 'E'], [inf, 'F'], [inf, 'G']] -
从 distances 数组选择最小值,则该值就是源点 s 到该值对应的顶点的最短路径,并且把该点加入到 nodes 中。
distances = {'A': 0, 'B': 4, 'C': 2, 'D': 3, 'E': inf, 'F': inf, 'G': inf} # 加入了A的近邻B,C,D nodes = [[2, 'C'], [3, 'D'], [4, 'B'], [inf, 'G'], [inf, 'E'], [inf, 'F']] # A被推出,更新B,C,D -
重复这个过程,直到 nodes 为 s 空或 nodes 中的最小值是无穷大(与剩下的节点都不连通)时。
代码
import heapq
class Graph:
def __init__(self):
self.vertices = {}
def add_vertex(self, name, edges):
self.vertices[name] = edges
def shortest_path(self, start, finish):
distances = {} # 记录各点到起点距离
previous = {} # 记录先前路径,注意:对于求最小路径时,每个点的先前路径是唯一的。
nodes = [] # 优先队列
for vertex in self.vertices:
if vertex == start: # 原点 s 的路径权重被赋为 0 (dis[s] = 0)。把到其他顶点的路径长度设为无穷大。
distances[vertex] = 0
heapq.heappush(nodes, [0, vertex])
else:
distances[vertex] = float('inf')
heapq.heappush(nodes, [float('inf'), vertex])
previous[vertex] = None
while nodes:
smallest = heapq.heappop(nodes)[1] # pop优先队列的第一个节点
if smallest == finish: # 保存路径
path = []
cur = smallest
while cur: # 循环到起点,其先前节点为None,结束
path.append(cur)
cur = previous[cur]
path.reverse()
if distances[smallest] == float('inf'): # 剩余所有节点已不相邻
break
for neighbor in self.vertices[smallest]: # 获取近邻节点
alt = distances[smallest] + self.vertices[smallest][neighbor]
if alt < distances[neighbor]: # 得到的路径比之前的近,则更新nodes,previous
previous[neighbor] = smallest
distances[neighbor] = alt
for n in nodes:
if n[1] == neighbor:
n[0] = alt
break
heapq.heapify(nodes)
#print(distances,nodes)
return distances[finish], path
def __str__(self):
return str(self.vertices)
if __name__ == '__main__':
# 实例化,这个类需要依次传入所有边。
g = Graph()
g.add_vertex('A', {'B': 4, 'C': 2, 'D': 3})
g.add_vertex('B', {'A': 4, 'E': 2, 'F': 5})
g.add_vertex('C', {'A': 2, 'G': 1})
g.add_vertex('D', {'A': 3, 'G': 2})
g.add_vertex('E', {'B': 2, 'F': 4})
g.add_vertex('F', {'B': 5, 'E': 4, 'G': 3})
g.add_vertex('G', {'C': 1, 'D': 2, 'F': 3})
print(g.shortest_path('A', 'G'))
4.2 Floyd-Warshall算法#
特点
Floyd-Warshall算法(Floyd-Warshall algorithm),中文亦称弗洛伊德算法,是解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权(但不可存在负权回路)的最短路径问题,同时也被用于计算有向图的传递闭包。
Floyd 算法是一个经典的动态规划算法。
设 $D_{i,j,k}$ 为从 $i$ 到 $j$ 的只以 $(i, j)$ 集合中的节点为中间节点的最短路径的长度。
- 若最短路径经过点k,则 $D_{i,j,k}=D_{i,k,k-1}+D_{k,j,k-1}$;
- 若最短路径不经过点k,则 $D_{i,j,k}=D_{i,j,k-1}$
因此,$D_{i,j,k}=min(D_{i,j,k-1},D_{i,k,k-1}+D_{k,j,k-1})$。
在实际算法中,为了节约空间,可以直接在原来空间上进行迭代,这样空间可降至二维。
流程
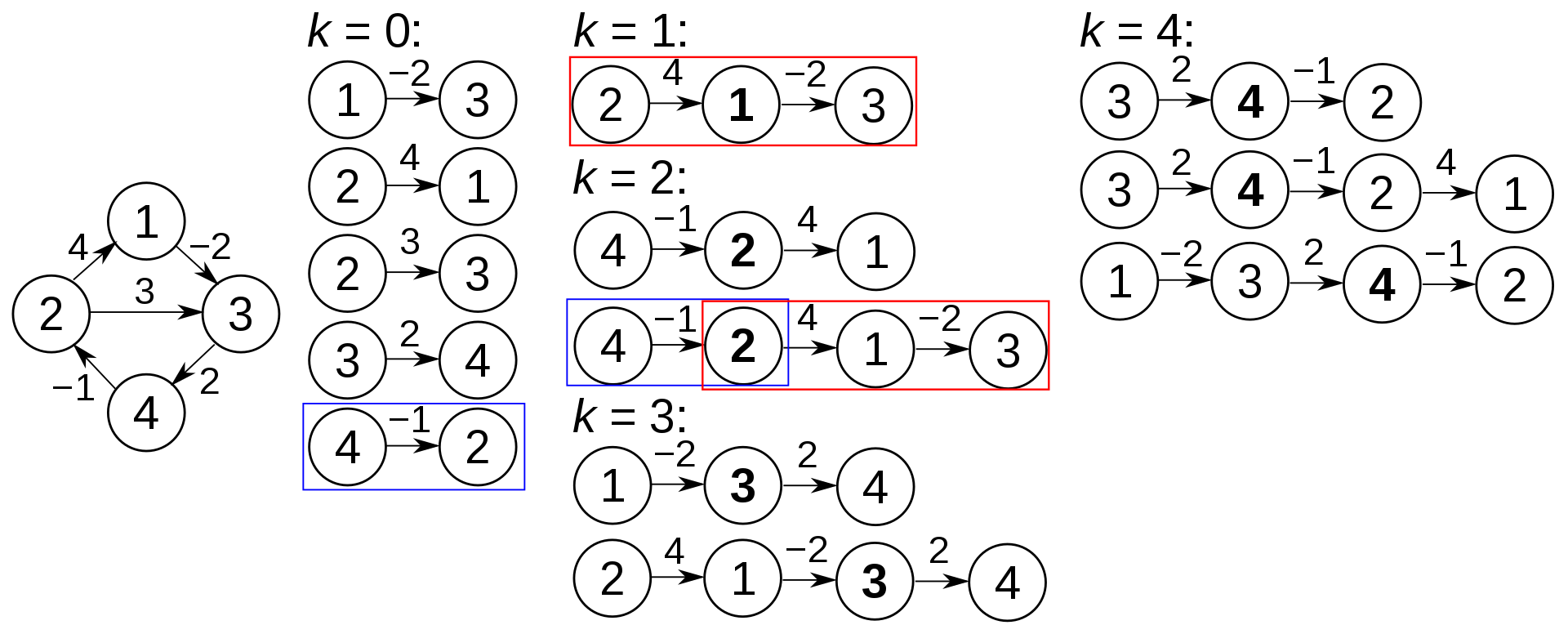

Floyd-Warshall算法的时间复杂度 为 $O(N^{3})$,空间复杂度 为 $O(N^{2})$。
代码
def floyd(graph):
length = len(graph)
path = {}
# 建立初始路径path
for i in range(length):
path[i] = {}
for j in range(length):
if i != j and graph[i][j] != float('inf'):
path[i][j] = [i, j]
# i为选取的中间节点
for i in range(length):
# j为中间节点i的前节点
for j in range(length):
if i == j:
continue
# k为中间节点i的后节点
for k in range(length):
if k == i or k == j:
continue
new_len = graph[j][i] + graph[i][k]
if graph[j][k] > new_len:
graph[j][k] = new_len
new_node = i
# 合并路径
path[j][k] = path[j][i][:-1] + path[i][k]
return graph, path
if __name__ == '__main__':
ini = float('inf')
graph_list = [
[0, ini, -2, ini],
[4, 0, 3, ini],
[ini, ini, 0, 2],
[ini, -1, ini, 0]
]
new_graph, path = floyd(graph_list)
print(new_graph, '\n\n\n', path)
五、生成树#
对连通图进行遍历,过程中所经过的边和顶点的组合可看做是一棵普通树,通常称为生成树。
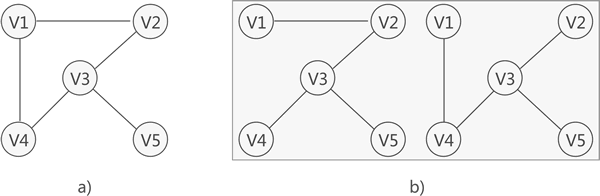
a) 是一张连通图,b) 是其对应的 2 种生成树。
连通图中,由于任意两顶点之间可能含有多条通路,遍历连通图的方式有多种,往往一张连通图可能有多种不同的生成树与之对应。
连通图中的生成树必须满足以下 2 个条件:
- 包含连通图中所有的顶点;
- 任意两顶点之间有且仅有一条通路;
因此,连通图的生成树具有这样的特征,即生成树中边的数量 = 顶点数 - 1。
5.1 Prim算法#
普里姆算法(Prim’s algorithm),图论中的一种算法,可在加权连通图里搜索最小生成树。意即由此算法搜索到的边子集所构成的树中,不但包括了连通图里的所有顶点,且其所有边的权值之和亦为最小。
流程
- 输入:一个加权连通图,其中顶点集合为 V,边集合为 E
- 初始化:Vnew = {x},其中 x 为集合 V 中的任一节点(起始点),Enew = {} 为空
- 在集合 E 中选取权值最小的边 <u, v>,其中 u 为集合 Vnew 中的元素,而 v 不在 Vnew 集合当中,并且 v∈V (如果存在有多条满足前述条件即具有相同权值的边,则可任意选取其中之一)
- 将 v 加入集合 Vnew 中,将 <u, v> 边加入集合 Enew 中
- 重复步骤 3、4 直到 Vnew = V
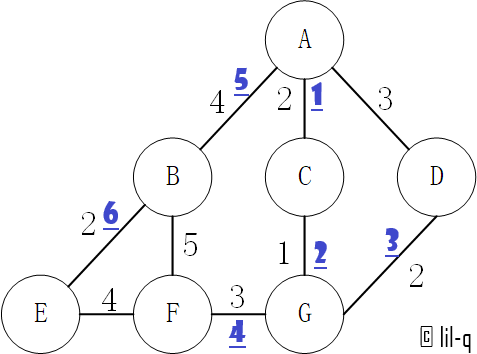
时间复杂度:$O(V^2)$。
代码
def prim(graph, root):
assert type(graph)==dict
nodes = list(graph)
nodes.remove(root)
visited = [root]
path = []
next = None
while nodes:
distance = float('inf')
for s in visited:
for d in graph[s]:
if d in visited or s == d:
continue
if graph[s][d] < distance:
distance = graph[s][d]
pre = s
next = d
path.append((pre, next))
visited.append(next)
nodes.remove(next)
return path
if __name__ == '__main__':
ini = float('inf')
graph_dict = { 'A': {'A': ini, 'B': 4, 'C': 2, 'D': 3, 'E': ini, 'F': ini, 'G': ini},
'B': {'A': 4, 'B': ini, 'C': ini, 'D': ini, 'E': 2, 'F': 5, 'G': ini},
'C': {'A': 2, 'B': ini, 'C': ini, 'D': ini, 'E': ini, 'F': ini, 'G': 1 },
'D': {'A': 3, 'B': ini, 'C': ini, 'D': ini, 'E': ini, 'F': ini, 'G': 2 },
'E': {'A': ini, 'B': 2, 'C': ini, 'D': ini, 'E': ini, 'F': 4, 'G': ini},
'F': {'A': ini, 'B': 5, 'C': ini, 'D': ini, 'E': 4, 'F': ini, 'G': 3 },
'G': {'A': ini, 'B': ini, 'C': 1, 'D': 2, 'E': ini, 'F': 3, 'G': ini},
}
path = prim(graph_dict, 'A')
print("path:", path)
可以看到输出顺序和上图是一致的:
path: [('A', 'C'), ('C', 'G'), ('G', 'D'), ('G', 'F'), ('A', 'B'), ('B', 'E')]
5.2 Kruskal算法#
Kruskal算法是一种用来查找最小生成树的算法,由Joseph Kruskal在1956年发表。基于并查集 的数据结构。
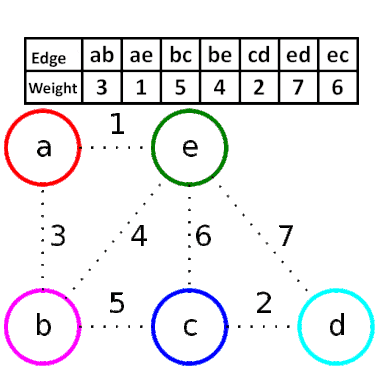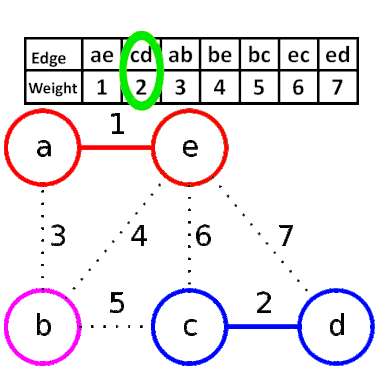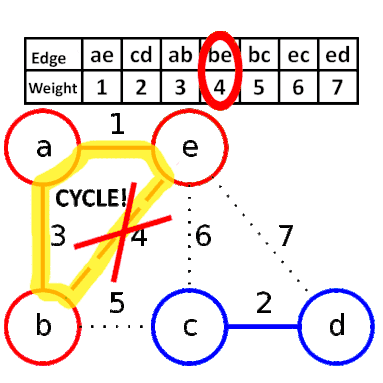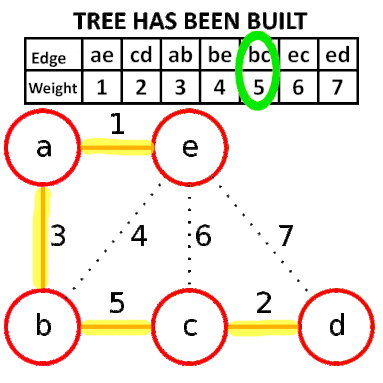
流程
- 新建图 $G$,$G$ 中拥有原图中相同的节点,但没有边
- 将原图中所有的边按权值从小到大排序
- 从权值最小的边开始,如果这条边连接的两个节点于图 $G$ 中不在同一个连通分量中,则添加这条边到图 $G$ 中
- 重复3,直至图 $G$ 中所有的节点都在同一个连通分量中
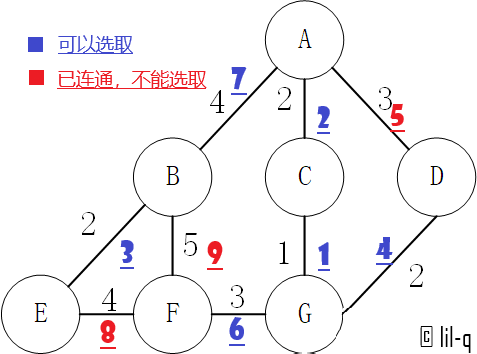
代码
def find(id, p):
while p != id[p]:
id[p] = id[id[p]]
p = id[p]
return p
def union(id, size, p, q):
root_p = find(id, p)
root_q = find(id, q)
if root_p != root_q:
if size[p] < size[q]:
id[root_p] = root_q
size[q] += size[p]
else:
id[root_q] = root_p
size[p] += size[q]
def kruskal(graph):
assert type(graph)==dict
edges = [(graph[u][v], u, v) for u in graph for v in graph[u] if graph[u][v] != float('inf')]
path = []
id, size = {u:u for u in graph}, {u:0 for u in graph}
for _, u, v in sorted(edges):
if find(id, u) != find(id, v):
path.append((u, v))
union(id, size, u, v)
return path
输入与理论一致:
path: [('C', 'G'), ('A', 'C'), ('B', 'E'), ('D', 'G'), ('F', 'G'), ('A', 'B')]