Java:面向对象和异常处理
一、面向对象#
Java 是一种面向对象的编程语言。面向对象程序设计(Object-Oriented Programming,OOP)是一种具有对象概念的程序编程典范,同时也是一种程序开发的抽象方针。
1.1 权限修饰符#
| 本类 | 同一个包下(子类和无关类) | 不同包下(子类) | 不同包下(无关类) | |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
一个 .java 文件只能包含一个 public 类,但可以包含多个非 public 类。如果有 public 类,文件名必须和 public 类的名字相同。
1.2 继承#
如果父类没有默认的构造方法,子类就必须显式调用 super() 并给出参数以便让编译器定位到父类的一个合适的构造方法。
子类不会继承任何父类的构造方法。子类默认的构造方法是编译器自动生成的,不是继承的。
- 向上转型(upcasting):一个子类类型安全地变为父类类型的赋值。
- 向下转型(downcasting):一个父类类型强制转型为子类类型。
向上转型只能够调用子类重写的方法;找回向上转型时丢失的子类扩展方法。instanceof 判断一个变量所指向的实例是否是指定类型,或者这个类型的子类。如果一个引用变量为 null,那么对任何 instanceof 的判断都为 false。
利用 instanceof,在向下转型前可以先判断:
Person p = new Student();
if (p instanceof Student) {
// 只有判断成功才会向下转型:
Student s = (Student) p; // 一定会成功
}
从 Java 14 开始,判断 instanceof 后,可以直接转型为指定变量,避免再次强制转型。
1.3 Override & Overload#
1. 重写(Override)
存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
为了满足里式替换原则,重写有以下三个限制:
- 子类方法的访问权限必须大于等于父类方法;
- 子类方法的返回类型必须是父类方法返回类型或为其子类型。
- 子类方法抛出的异常类型必须是父类抛出异常类型或为其子类型。
使用 @Override 注解,可以让编译器帮忙检查是否满足上面的三个限制条件。
下面的示例中,SubClass 为 SuperClass 的子类,SubClass 重写了 SuperClass 的 func() 方法。其中:
- 子类方法访问权限为 public,大于父类的 protected。
- 子类的返回类型为 ArrayList,是父类返回类型 List 的子类。
- 子类抛出的异常类型为 Exception,是父类抛出异常 Throwable 的子类。
- 子类重写方法使用
@Override注解,从而让编译器自动检查是否满足限制条件。
class SuperClass {
protected List<Integer> func() throws Throwable {
return new ArrayList<>();
}
}
class SubClass extends SuperClass {
@Override
public ArrayList<Integer> func() throws Exception {
return new ArrayList<>();
}
}
在调用一个方法时,先从本类中查找看是否有对应的方法,如果没有再到父类中查看,看是否从父类继承来。否则就要对参数进行转型,转成父类之后看是否有对应的方法。总的来说,方法调用的优先级为:
this.func(this)super.func(this)this.func(super)super.func(super)
/*
A
|
B
|
C
|
D
*/
class A {
public void show(A obj) {
System.out.println("A.show(A)");
}
public void show(C obj) {
System.out.println("A.show(C)");
}
}
class B extends A {
@Override
public void show(A obj) {
System.out.println("B.show(A)");
}
}
class C extends B {
}
class D extends C {
}
public static void main(String[] args) {
A a = new A();
B b = new B();
C c = new C();
D d = new D();
// 在 A 中存在 show(A obj),直接调用
a.show(a); // A.show(A)
// 在 A 中不存在 show(B obj),将 B 转型成其父类 A
a.show(b); // A.show(A)
// 在 B 中存在从 A 继承来的 show(C obj),直接调用
b.show(c); // A.show(C)
// 在 B 中不存在 show(D obj),但是存在从 A 继承来的 show(C obj),将 D 转型成其父类 C
b.show(d); // A.show(C)
// 引用的还是 B 对象,所以 ba 和 b 的调用结果一样
A ba = new B();
ba.show(c); // A.show(C)
ba.show(d); // A.show(C)
}
在子类的覆写方法中,如果要调用父类的被覆写的方法,可以通过 super 来调用。
2. 重载(Overlode)
Override 和 Overload 不同的是,如果方法签名如果不同,就是 Overload,Overload 方法是一个新方法;如果方法签名相同,并且返回值也相同,就是 Override。
1.4 Object方法#
因为所有的 Class 最终都继承自 Object,而 Object 定义了几个重要的方法:
1. equals()
- 对于基本类型,== 判断两个值是否相等,基本类型没有
equals()方法。 - 对于引用类型,== 判断是否引用同一个对象,而
equals()判断引用的对象是否等价。
equals() 具有以下性质(x,y & z 非 null):
- 自反性(Reflexive):
x.equals(x)必须返回 true; - 对称性(Symmetric):
x.equals(y)为 true,则y.equals(x)也必须为 true; - 传递性(Transitive):
x.equals(y)和y.equals(z)结果可得出x.equals(z); - 一致性(Consistent): x 和 y 状态不变,则
x.equals(y)结论总是一致; - 对 null 的比较:即
x.equals(null)永远返回 false。
public class EqualExample {
private int x;
private int y;
private int z;
public EqualExample(int x, int y, int z) {
this.x = x;
this.y = y;
this.z = z;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
EqualExample that = (EqualExample) o;
if (x != that.x) return false;
if (y != that.y) return false;
return z == that.z;
}
}
2. hashCode()
hashCode() 返回哈希值,而 equals() 是用来判断两个对象是否等价。等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定等价,这是因为计算哈希值具有随机性,两个值不同的对象可能计算出相同的哈希值。
在覆盖 equals() 方法时必须覆盖 hashCode() 方法,保证等价的两个对象哈希值也相等。
HashSet 和 HashMap 等集合类使用了 hashCode() 方法来计算对象应该存储的位置,因此要将对象添加到这些集合类中,需要让对应的类实现 hashCode() 方法。
下面的代码中,新建了两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个对象。但是 EqualExample 没有实现 hashCode() 方法,因此这两个对象的哈希值是不同的,最终导致集合添加了两个等价的对象。
EqualExample e1 = new EqualExample(1, 1, 1);
EqualExample e2 = new EqualExample(1, 1, 1);
System.out.println(e1.equals(e2)); // true
HashSet<EqualExample> set = new HashSet<>();
set.add(e1);
set.add(e2);
System.out.println(set.size()); // 2
理想的哈希函数应当具有均匀性,即不相等的对象应当均匀分布到所有可能的哈希值上。这就要求了哈希函数要把所有域的值都考虑进来。可以将每个域都当成 R 进制的某一位,然后组成一个 R 进制的整数。
R 一般取 31,因为它是一个奇素数,如果是偶数的话,当出现乘法溢出,信息就会丢失,因为与 2 相乘相当于向左移一位,最左边的位丢失。并且一个数与 31 相乘可以转换成移位和减法: 31 * x == (x « 5) - x,编译器会自动进行这个优化。
@Override
public int hashCode() {
int result = 17;
result = 31 * result + x;
result = 31 * result + y;
result = 31 * result + z;
return result;
}
3. toString()
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
4. clone()
(1)cloneable
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。
重写 clone() 需要实现 Cloneable 接口。应该注意的是,clone()方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了clone()方法,就会抛出 CloneNotSupportedException。
public class CloneExample implements Cloneable {
private int a;
private int b;
@Override
public Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
拷贝分为深拷贝和浅拷贝,两种方式生成的对象的地址是不同的,这有别于赋值。
(2)浅拷贝
拷贝对象和原始对象的引用类型引用同一个对象。
public class ShallowCloneExample implements Cloneable {
private int[] arr;
public ShallowCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected ShallowCloneExample clone() throws CloneNotSupportedException {
return (ShallowCloneExample) super.clone();
}
}
ShallowCloneExample e1 = new ShallowCloneExample();
ShallowCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 222
(3)深拷贝
拷贝对象和原始对象的引用类型引用不同对象。
public class DeepCloneExample implements Cloneable {
private int[] arr;
public DeepCloneExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
@Override
protected DeepCloneExample clone() throws CloneNotSupportedException {
DeepCloneExample result = (DeepCloneExample) super.clone();
result.arr = new int[arr.length];
for (int i = 0; i < arr.length; i++) {
result.arr[i] = arr[i];
}
return result;
}
}
DeepCloneExample e1 = new DeepCloneExample();
DeepCloneExample e2 = null;
try {
e2 = e1.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
e1.set(2, 222);
System.out.println(e2.get(2)); // 2
(4)clone() 的替代方案
使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者拷贝工厂来拷贝一个对象。
public class CloneConstructorExample {
private int[] arr;
public CloneConstructorExample() {
arr = new int[10];
for (int i = 0; i < arr.length; i++) {
arr[i] = i;
}
}
public CloneConstructorExample(CloneConstructorExample original) {
arr = new int[original.arr.length];
for (int i = 0; i < original.arr.length; i++) {
arr[i] = original.arr[i];
}
}
public void set(int index, int value) {
arr[index] = value;
}
public int get(int index) {
return arr[index];
}
}
CloneConstructorExample e1 = new CloneConstructorExample();
CloneConstructorExample e2 = new CloneConstructorExample(e1);
e1.set(2, 222);
System.out.println(e2.get(2)); // 2
1.5 抽象类和接口#
接口和抽象类都是继承树的上层,他们的共同点如下:
- 都是上层的抽象层。
- 都不能被实例化。
- 都能包含抽象的方法,这些抽象的方法用于描述类具备的功能,但不提供具体的实现。
1. 抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明,抽象方法默认 public 修饰,不能使用 private。如果一个类中包含抽象方法,那么这个类必须声明为抽象类。抽象类可以没有抽象方法,可以拥有 private 修饰的成员(非抽象方法)。
抽象类和普通类最大的区别是,抽象类不能被实例化,只能被继承。
因为抽象类本身被设计成只能用于被继承,因此,抽象类可以强迫子类实现其定义的抽象方法,否则编译会报错。因此,抽象方法实际上相当于设计了模板。
2. 接口
接口是抽象类的延伸,在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类,让它们都实现新增的方法。
- 接口的成员(字段 + 方法)默认都是 public 的,不允许定义为 private 或者 protected。
- 接口的字段默认都是 static 和 final 的。
3. 接口和抽象类的区别:
- 从设计层面上看,抽象类提供了一种 IS-A 关系,需要满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
4. 使用选择
使用接口:
- 需要让不相关的类都实现一个方法,例如 Compareable 接口中的
compareTo()方法; - 需要使用多重继承。
使用抽象类:
- 需要在几个相关的类中共享代码。
- 需要能控制继承来的成员的访问权限,而不是都为 public。
- 需要继承非静态和非常量字段。
在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
1.6 包#
包没有父子关系。java.util 和 java.util.zip 是不同的包,两者没有任何继承关系。
Java 编译器最终编译出的 .class 文件只使用完整类名,因此,在代码中,当编译器遇到一个 Class 名称时:
-
如果是完整类名,就直接根据完整类名查找这个 Class;
-
如果是简单类名,按下面的顺序依次查找:
- 查找当前 package 是否存在这个 Class;
- 查找 import 的包是否包含这个 Class;
- 查找 java.lang 包是否包含这个 Class。
如果按照上面的规则还无法确定类名,则编译报错。
编写 Class 的时候,编译器会自动帮我们做两个 import 动作:
- 默认自动 import 当前 package 的其他 Class;
- 默认自动
import java.lang.*。
1.7 模块#
从 Java 9 开始,JDK 又引入了模块(Module)。把一堆 Class 封装为 jar 仅仅是一个打包的过程,而把一堆 Class 封装为模块则不但需要打包,还需要写入依赖关系,并且还可以包含二进制代码(通常是 JNI 扩展)。此外,模块支持多版本,即在同一个模块中可以为不同的 JVM 提供不同的版本。
二、异常处理#
Java 把异常当作对象来处理,并定义一个基类 java.lang.Throwable 作为所有异常的超类。Throwable 可以用来表示任何可以作为异常抛出的类,分为两种: Error 和 Exception。其中 Error 用来表示 JVM 无法处理的错误。
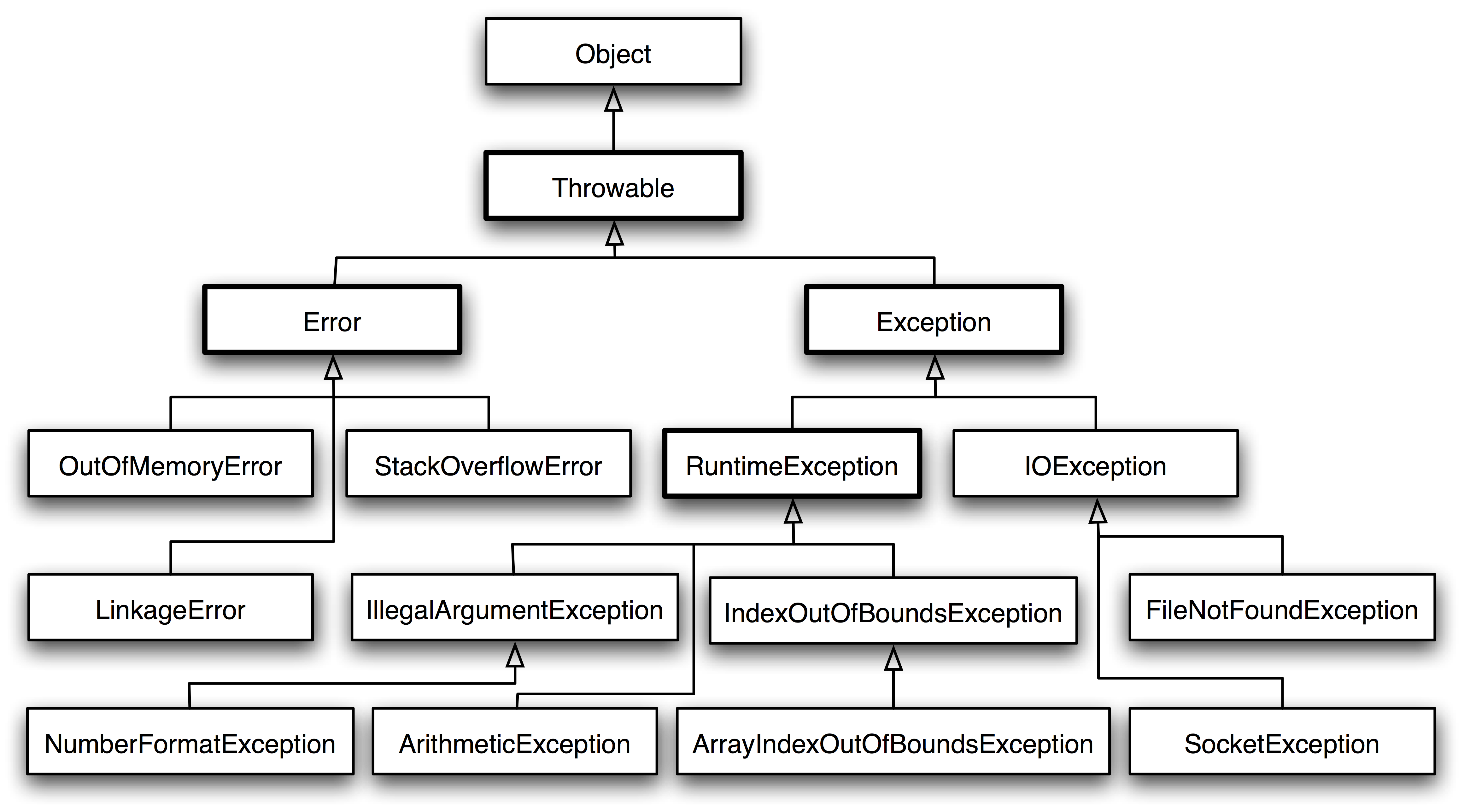
从图中可以看出所有异常类型都是内置类 Throwable 的子类,因而 Throwable 在异常类的层次结构的顶层。接下来 Throwable 分成了两个不同的分支,一个分支是 Error,它表示不希望被程序捕获或者是程序无法处理的错误。另一个分支是 Exception,它表示用户程序可能捕捉的异常情况或者说是程序可以处理的异常。其中异常类 Exception 又分为运行时异常(RuntimeException)和非运行时异常。Java 异常又可以分为不受检查异常(Unchecked Exception)和检查异常(Checked Exception)。
2.1 Error & Exception#
- Error 通常是灾难性的致命的错误,是程序无法控制和处理的,当出现这些异常时,Java 虚拟机(JVM)一般会选择终止线程;
- Exception 通常情况下是可以被程序处理的,并且在程序中应该尽可能的去处理这些异常。
2.2 检查异常 & 不受检查异常#
- 受检查异常:除了 RuntimeException 及其子类以外,其他的 Exception 类及其子类都属于这种异常,当程序中可能出现这类异常,要么使用 try-catch 语句进行捕获,要么用 throws 子句抛出,否则编译无法通过。
- 不受检查异常:包括 RuntimeException 及其子类和 Error。
对于运行时异常、错误和检查异常,Java 技术所要求的异常处理方式有所不同。
由于运行时异常及其子类的不可查性,为了更合理、更容易地实现应用程序,Java 规定,运行时异常将由 Java 运行时系统自动抛出,允许应用程序忽略运行时异常。
对于方法运行中可能出现的 Error,当运行方法不欲捕捉时,Java 允许该方法不做任何抛出声明。因为,大多数 Error 异常属于永远不能被允许发生的状况,也属于合理的应用程序不该捕捉的异常。
对于所有的检查异常,Java 规定:一个方法必须捕捉,或者声明抛出方法之外。也就是说,当一个方法选择不捕捉检查异常时,它必须声明将抛出异常。
2.3 Java 中异常处理机制#
Java 的异常处理本质上是抛出异常和捕获异常。
抛出异常:异常情形出现时,程序已经无法继续下去了,因为在当前环境下无法获得必要的信息来解决问题,所能做的就是从当前环境中跳出,并把问题提交给上一级环境,这就是抛出异常时所发生的事情。抛出异常后,会有几件事随之发生。首先,是像创建普通的 Java 对象一样将使用 new 在堆上创建一个异常对象;然后,当前的执行路径(已经无法继续下去了)被终止,并且从当前环境中弹出对异常对象的引用。此时,异常处理机制接管程序,并开始寻找一个恰当的地方继续执行程序,这个恰当的地方就是异常处理程序或者异常处理器,它的任务是将程序从错误状态中恢复,以使程序要么换一种方式运行,要么继续运行下去。
捕获异常:在方法抛出异常之后,运行时系统将转为寻找合适的异常处理器(exception handler)。潜在的异常处理器是异常发生时依次存留在调用栈中的方法的集合。当异常处理器所能处理的异常类型与方法抛出的异常类型相符时,即为合适的异常处理器。运行时系统从发生异常的方法开始,依次回查调用栈中的方法,直至找到含有合适异常处理器的方法并执行。当运行时系统遍历调用栈而未找到合适的异常处理器,则运行时系统终止。同时,意味着 Java 程序的终止。
2.4 异常处理基本语法#
- try:用来指定一块预防所有异常的程序(监控区域);
- catch:紧跟在try后面,用来捕获异常;
- throw:用来明确的抛出一个异常;
- throws:用来标明一个成员函数可能抛出的各种异常;
- finally:确保一段代码无论发生什么异常都会被执行的一段代码。
注意 finally 有几个特点:
- finally 语句不是必须的,可写可不写;
- finally 总是最后执行。
如果没有发生异常,就正常执行 try { ... } 语句块,然后执行 finally。如果发生了异常,就中断执行 try { ... } 语句块,然后跳转执行匹配的 catch 语句块,最后执行 finally。可见,finally 是用来保证一些代码必须执行的。
某些情况下,可以没有 catch,只使用 try ... finally 结构。例如:
void process(String file) throws IOException {
try {
...
} finally {
System.out.println("END");
}
}
因为方法声明了可能抛出的异常,所以可以不写 catch。
2.5 异常处理要领#
- 尽量避免出现 RuntimeException。例如对于可能出现空指针的代码,带使用对象之前一定要判断一下该对象是否为空,必要的时候对 RuntimeException 也进行 try-catch 处理。
- 进行 try-catch 处理的时候要在 catch 代码块中对异常信息进行记录,通过调用异常类的相关方法获取到异常的相关信息,返回到 web 端,不仅要给用户良好的用户体验,也要能帮助程序员良好的定位异常出现的位置及原因。例如,以前做的一个项目,程序遇到异常页面会显示一个图片告诉用户哪些操作导致程序出现了什么异常,同时图片上有一个按钮用来点击展示异常的详细信息给程序员看的。
2.6 final、finally & finalize#
- final 用于声明变量、方法和类的,分别表示变量值不可变,方法不可覆盖,类不可以继承;
- finally 是异常处理中的一个关键字,表示
finally{...}里面的代码一定要执行; - finalize 是 Object 类的一个方法,在垃圾回收的时候会调用被回收对象的此方法。