Java:Collection
容器主要包括 Collection 和 Map 两种,Collection 存储着对象的集合,而 Map 存储着键值对(两个对象)的映射表。【以下内容源码基于 Java 13】
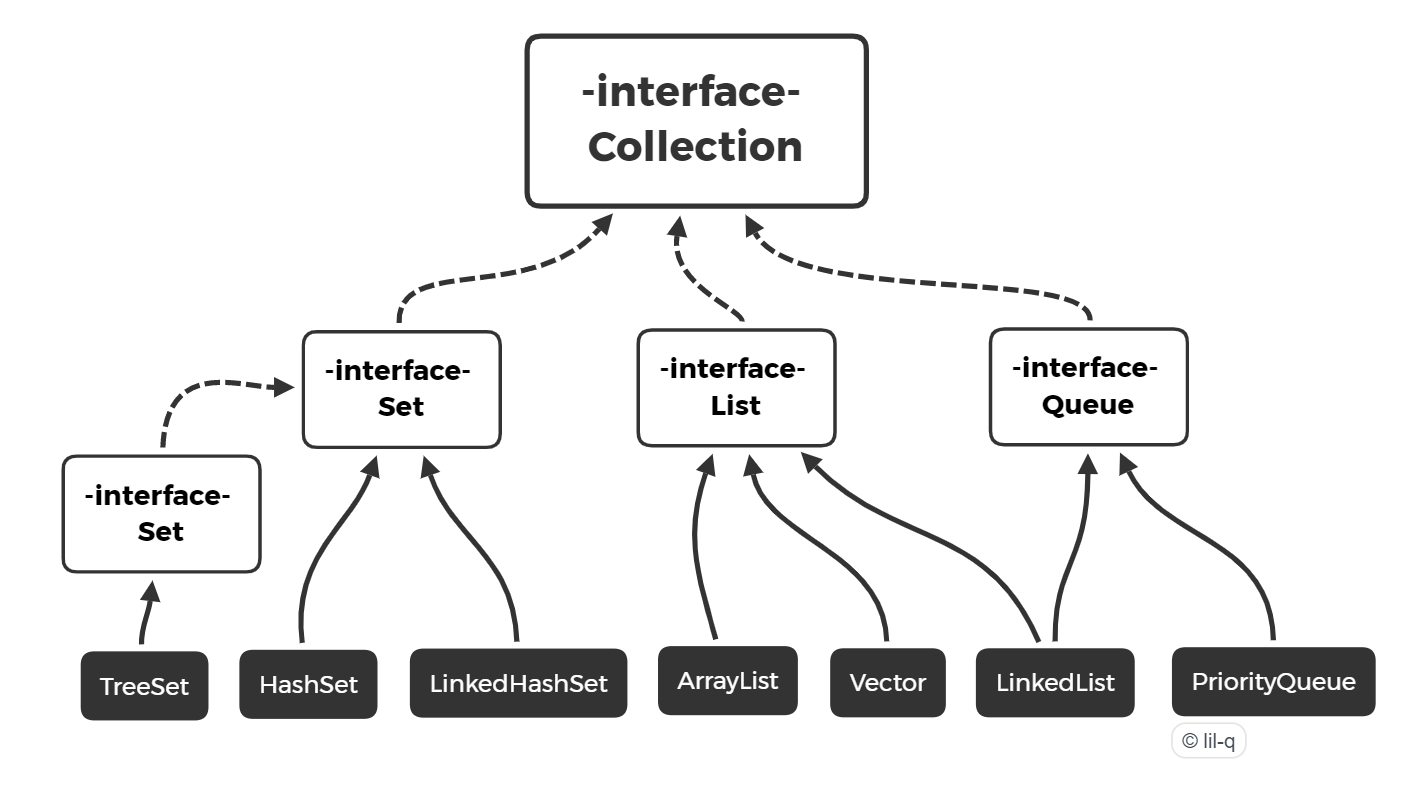
一、Collection#
二、List#
List 接口有几个主要的接口方法:
- 在末尾添加一个元素:
void add(E e); - 在指定索引添加一个元素:
void add(int index, E e); - 删除指定索引的元素:
int remove(int index); - 删除某个元素:
int remove(Object e); - 获取指定索引的元素:
E get(int index); - 获取链表大小(包含元素的个数):
int size()。
List 接口允许我们添加重复的元素,即 List 内部的元素可以重复,List 还允许添加 null。调用 List.of(),它返回的是一个只读 List:
List<Integer> list = List.of(1, 2, 5);
但是 List.of() 方法不接受 null 值,如果传入 null,会抛出 NullPointerException 异常。
2.1 List 遍历#
List 的遍历采用了迭代器的设计模式:
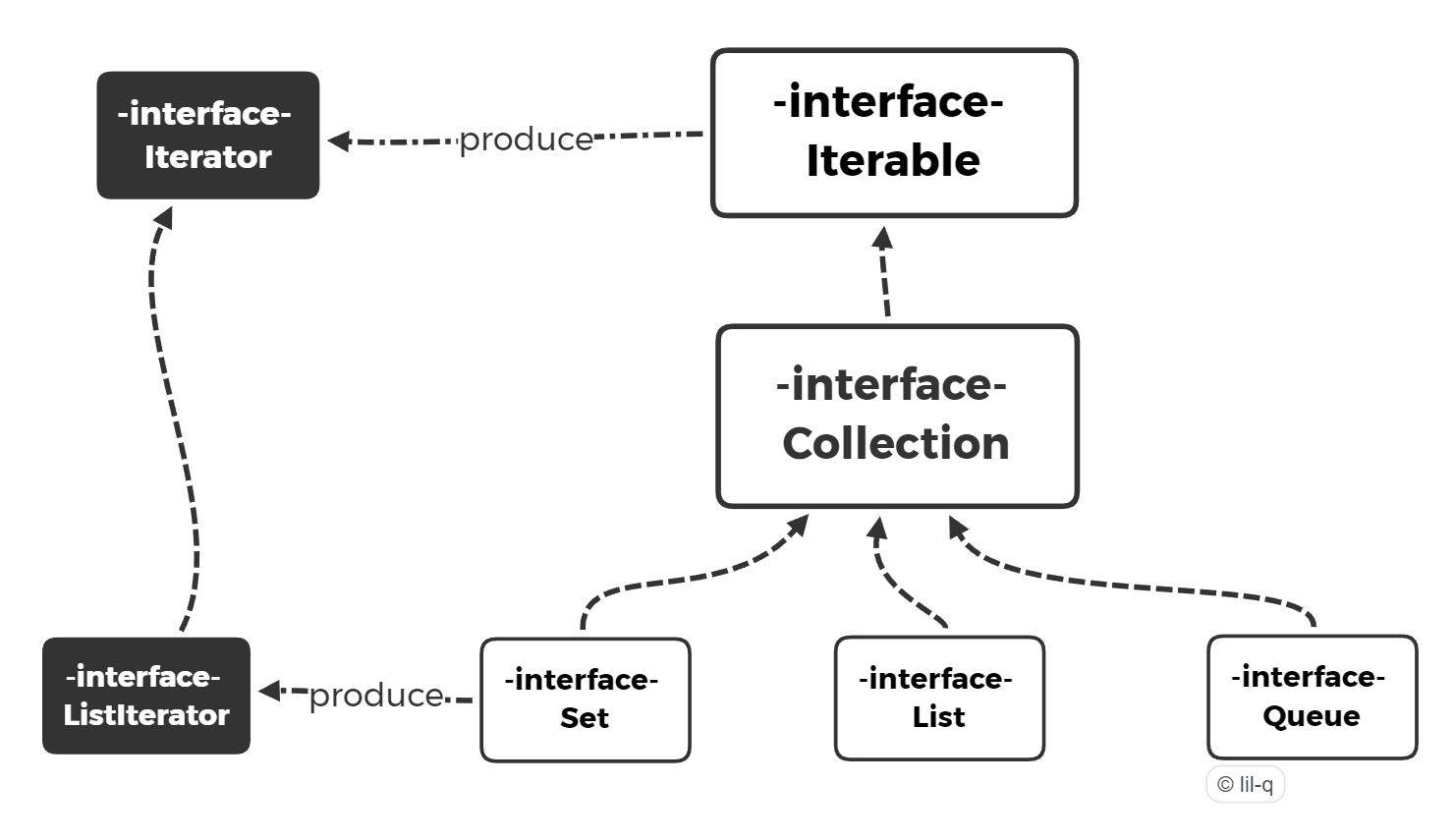
Iterable 接口声明如下:
public interface Iterable<T> {
Iterator<T> iterator();
}
Iterator 接口声明如下:
public interface Iterator<E> {
// 判断是否还有下一个对象,如果有,则返回 true,否则 false
boolean hasNext();
// 返回集合的下个值,此方法只能在 hasNext 方法返回 true 时调用
E next();
// 删除集合的当前值,此方法也只能在 hasNext 方法返回 true 时调用
void remove();
}
ListIterator 接口声明如下:
public interface ListIterator<E> extends Iterator<E> {
// 支持双向移动
boolean hasNext();
E next();
boolean hasPrevious();
E previous();
// 产生相对于迭代器在列表中指向的当前位置的前一个和后一个元素的索引
int nextIndex();
int previousIndex();
void remove();
// 可以使用 set() 方法替换它访问过的最后一个元素
void set(E e);
// 可以使用 add() 方法在 next() 方法返回的元素之前或 previous() 方法返回的元素之后插入一个元素
void add(E e);
}
通过 Iterator 遍历 List 永远是最高效的方式。并且,由于 Iterator 遍历是如此常用,所以,Java 的 for each 循环本身就可以帮我们使用 Iterator 遍历。
import java.util.Iterator;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
System.out.println(s);
}
}
}
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (String s : list) {
System.out.println(s);
}
}
}
2.2 List 和 Array 转换#
1. List -> Array
给 toArray(T[]) 传入一个类型相同的 Array,List 内部自动把元素复制到传入的 Array 中:
import java.util.List;
public class Main {
public static void main(String[] args) {
List<Integer> list = List.of(12, 34, 56);
Integer[] array = list.toArray(new Integer[3]);
for (Integer n : array) {
System.out.println(n);
}
}
}
toArray(T[]) 方法的泛型参数 T 并不是 List 接口定义的泛型参数 E,所以,我们实际上可以传入其他类型的数组。
Number[] array = list.toArray(new Number[3]);
如果传入的数组不够大,那么 List 内部会创建一个新的刚好够大的数组,填充后返回;如果传入的数组比 List 元素还要多,那么填充完元素后,剩下的数组元素一律填充 null。实际上,最常用的是传入一个 “恰好” 大小的数组:
Integer[] array = list.toArray(new Integer[list.size()]);
2. Array -> List
Integer[] array = { 1, 2, 3 };
List<Integer> list = List.of(array);
对于 JDK 11 之前的版本,可以使用 Arrays.asList(T...) 方法把 Array 转换成 List。
2.3 contains()#
List 内部按照放入元素的先后顺序存放,并且每个元素都可以通过索引确定自己的位置。List 提供了 boolean contains(Object o) 方法来判断 List 是否包含某个指定元素。此外,int indexOf(Object o) 方法可以返回某个元素的索引,如果元素不存在,就返回 -1。
List 内部并不是通过 == 判断两个元素是否相等,而是使用 equals() 方法判断两个元素是否相等,所以放入的实例必须要正确 override。
如果 this.name 为 null,那么 equals() 方法会报错,因此,需要继续改写如下:
public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
boolean nameEquals = false;
if (this.name == null && p.name == null) {
nameEquals = true;
}
if (this.name != null) {
nameEquals = this.name.equals(p.name);
}
return nameEquals && this.age == p.age;
}
return false;
}
如果 Person 有好几个引用类型的字段,上面的写法就太复杂了。要简化引用类型的比较,我们使用 Objects.equals() 静态方法:
public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
return Objects.equals(this.name, p.name) && this.age == p.age;
}
return false;
}
2.4 List 实现类#
- ArrayList:基于动态数组,支持随机访问。
- Vector:和 ArrayList 类似,线程安全。
- LinkedList:基于双向链表实现,只能顺序访问,但是可以快速地在链表中间插入和删除元素。不仅如此,LinkedList 还可以用作栈、队列和双向队列。
比较 ArrayList 和 LinkedList:
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加/删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
通常情况下,我们总是优先使用 ArrayList。
1. ArrayList
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
// Default initial capacity
private static final int DEFAULT_CAPACITY = 10;
...
RandomAccess 接口标识着该类支持快速随机访问,java.io.Serializable 是支持序列化接口。数组的默认大小为 10。
(1)扩容
添加元素时如果容量不够时,需要使用 grow() 方法进行扩容,新容量的大小默认为 oldCapacity + (oldCapacity » 1),也就是旧容量的 1.5 倍。当需求的容量大于它时,则会选用两个 List 长度之和作为新容量,扩容操作需要调用 Arrays.copyOf() 把原数组整个复制到新数组中,这个操作代价很高,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
modCount++;
int numNew = a.length;
if (numNew == 0)
return false;
Object[] elementData;
final int s;
// 加入的数组长度大于剩余空数组长度
if (numNew > (elementData = this.elementData).length - (s = size))
elementData = grow(s + numNew);
System.arraycopy(a, 0, elementData, s, numNew);
size = s + numNew;
return true;
}
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
private Object[] grow() {
return grow(size + 1);
}
ArraySupport 下的 newLength():
public static int newLength(int oldLength, int minGrowth, int prefGrowth) {
// assert oldLength >= 0
// assert minGrowth > 0
int newLength = Math.max(minGrowth, prefGrowth) + oldLength;
if (newLength - MAX_ARRAY_LENGTH <= 0) {
return newLength;
}
return hugeLength(oldLength, minGrowth); // 处理溢出情况
}
Arrays 下的 copyOf():
@SuppressWarnings("unchecked")
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
@HotSpotIntrinsicCandidate
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
System 下的 arraycopy():
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
(2)删除
remove() 调用了 fastRemove(),其中调用 System.arraycopy() 将 index + 1 后面的元素都复制到 index 位置上,该操作的时间复杂度为 O(N),所以 ArrayList 删除元素的代价是非常高的。
public E remove(int index) {
Objects.checkIndex(index, size);
final Object[] es = elementData;
@SuppressWarnings("unchecked") E oldValue = (E) es[index];
fastRemove(es, index);
return oldValue;
}
private void fastRemove(Object[] es, int i) {
modCount++;
final int newSize;
if ((newSize = size - 1) > i)
System.arraycopy(es, i + 1, es, i, newSize - i);
es[size = newSize] = null;
}
(3)序列化
保存元素的数组 elementData 使用 transient 修饰,该关键字声明数组默认不会被序列化。也就是说 elementData 的生命周期仅存于调用者的内存中而不会写到磁盘里持久化。
transient Object[] elementData; // non-private to simplify nested class access
ArrayList 实现了 writeObject() 和 readObject() 来控制只序列化数组中有元素填充那部分内容。
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in size, and any hidden stuff
s.defaultReadObject();
// Read in capacity
s.readInt(); // ignored
if (size > 0) {
// like clone(), allocate array based upon size not capacity
SharedSecrets.getJavaObjectInputStreamAccess().checkArray(s, Object[].class, size);
Object[] elements = new Object[size];
// Read in all elements in the proper order.
for (int i = 0; i < size; i++) {
elements[i] = s.readObject();
}
elementData = elements;
} else if (size == 0) {
elementData = EMPTY_ELEMENTDATA;
} else {
throw new java.io.InvalidObjectException("Invalid size: " + size);
}
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out element count, and any hidden stuff
int expectedModCount = modCount;
s.defaultWriteObject();
// Write out size as capacity for behavioral compatibility with clone()
s.writeInt(size);
// Write out all elements in the proper order.
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
序列化时需要使用 ObjectOutputStream 的 writeObject() 将对象转换为字节流并输出。而 writeObject() 方法在传入的对象存在 writeObject() 的时候会去反射调用该对象的 writeObject() 来实现序列化。反序列化使用的是 ObjectInputStream 的 readObject() 方法,原理类似。
ArrayList list = new ArrayList();
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(file));
oos.writeObject(list);
(4)fail-fast 机制
AbstractList 中使用 modCount 来记录 ArrayList 结构发生变化的次数。结构发生变化是指添加或者删除至少一个元素的所有操作,或者是调整内部数组的大小,仅仅只是设置元素的值不算结构发生变化。
protected transient int modCount = 0;
迭代器在调用 next()、remove() 方法时都是调用 checkForComodification() 方法,它检测 modCount == expectedModCount ? 若不等则抛出 ConcurrentModificationException 异常,从而产生 fail-fast 机制。
有两种解决方案:
- 在遍历过程中所有涉及到改变 modCount 值的地方全部加上 synchronized 或者直接使用 Collections.synchronizedList(不推荐);
- 使用 CopyOnWriteArrayList 来替换 ArrayList。
(5)toArray()
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
注意到传入的 elementData 和返回值是 Object[],如果需要传回原格式:
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass()); // 利用反射
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
2. CopyOnWriteArrayList
(1)读写分离
写操作在一个复制的数组上进行,读操作还是在原始数组中进行,读写分离,互不影响。
写操作需要加锁,否则多线程写的时候会 Copy 出 N 个副本,防止并发写入时数据丢失。
写操作结束之后需要把原始数组指向新的复制数组。
public boolean add(E e) {
final ReentrantLock lock = this.lock;
// 获得锁
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
// 复制新数组
Object[] newElements = Arrays.copyOf(elements, len + 1);
// 插入新值
newElements[len] = e;
// 原来的引用指向新的数组
setArray(newElements);
return true;
} finally {
// 释放锁
lock.unlock();
}
}
final void setArray(Object[] a) {
array = a;
}Copy to clipboardErrorCopied
@SuppressWarnings("unchecked")
private E get(Object[] a, int index) {
return (E) a[index];
}
使用 CopyOnWriteMap 需要注意两件事情:
- 减少扩容开销:根据实际需要,初始化就确定 CopyOnWriteMap 的大小,避免在写入时 CopyOnWriteMap 扩容带来的开销。
- 使用批量添加:因为每次添加,容器每次都会进行复制,所以减少添加次数,可以减少容器的复制次数。如使用代码里的
addBlackList()方法。
(2)适用场景
CopyOnWriteArrayList 在写操作的同时允许读操作,大大提高了读操作的性能,因此很适合读多写少的应用场景。
但是 CopyOnWriteArrayList 有其缺陷:
- 内存占用:在写操作时需要复制一个新的数组,使得内存占用为原来的两倍左右;
- 数据不一致:读操作不能读取实时性的数据,因为部分写操作的数据还未同步到读数组中。
所以 CopyOnWriteArrayList 不适合内存敏感以及对实时性要求很高的场景。
(3)CopyOnWriteArrayList & Vector
Vector 是增删改查方法都加了 synchronized,保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性能就好于 Vector,CopyOnWriteArrayList 支持读多写少的并发情况。
三、Set#
Set 用于存储不重复的元素集合,它主要提供以下几个方法:
- 将元素添加进 Set:
boolean add(E e); - 将元素从 Set 删除:
boolean remove(Object e); - 判断是否包含元素:
boolean contains(Object e)。
有以下实现类:
- TreeSet:基于红黑树实现,支持有序性操作,例如根据一个范围查找元素的操作。但是查找效率不如 HashSet,HashSet 查找的时间复杂度为 O(1),TreeSet 则为 O(logN)。
- HashSet:基于哈希表实现,支持快速查找,但不支持有序性操作。并且失去了元素的插入顺序信息,也就是说使用 Iterator 遍历 HashSet 得到的结果是不确定的。
- LinkedHashSet:具有 HashSet 的查找效率,并且内部使用双向链表维护元素的插入顺序。
Set 接口并不保证有序,而 SortedSet 接口则保证元素是有序的:
- HashSet 是无序的,因为它实现了 Set 接口,并没有实现 SortedSet 接口;
- TreeSet 是有序的,因为它实现了 SortedSet 接口。
四、Queue#
Queue 实际上是实现了一个先进先出(First In First Out,FIFO)的有序表,队列接口 Queue 定义了以下几个方法:
int size():获取队列长度;boolean add(E)/boolean offer(E):添加元素到队尾;E remove()/E poll():获取队首元素并从队列中删除;E element()/E peek():获取队首元素但并不从队列中删除。
对于具体的实现类,有的 Queue 有最大队列长度限制,有的 Queue 没有。注意到添加、删除和获取队列元素总是有两个方法,这是因为在添加或获取元素失败时,这两个方法的行为是不同的。我们用一个表格总结如下:
| throw Exception | 返回 false 或 null | |
|---|---|---|
| 添加元素到队尾 | add(E e) | boolean offer(E e) |
| 取队首元素并删除 | E remove() | E poll() |
| 取队首元素但不删除 | E element() | E peek() |
4.1 Deque#
public interface Deque<E> extends Queue<E> {...}
Deque 实现了一个双端队列(Double Ended Queue),比较 Queue 和 Deque 出队和入队的方法:
| Queue | Deque | |
|---|---|---|
| 添加元素到队尾 | add(E e) / offer(E e) | addLast(E e) / offerLast(E e) |
| 取队首元素并删除 | E remove() / E poll() | E removeFirst() / E pollFirst() |
| 取队首元素但不删除 | E element() / E peek() | E getFirst() / E peekFirst() |
| 添加元素到队首 | 无 | addFirst(E e) / offerFirst(E e) |
| 取队尾元素并删除 | 无 | E removeLast() / E pollLast() |
| 取队尾元素但不删除 | 无 | E getLast() / E peekLast() |
4.2 Stack#
栈(Stack)是一种后进先出(LIFO:Last In First Out)的数据结构,操作栈的元素的方法有:
- 把元素压栈:
push(E); - 把栈顶的元素“弹出”:
pop(E); - 取栈顶元素但不弹出:
peek(E)。
用 Deque 可以实现 Stack 的功能,注意只调用push()/pop()/peek()方法,避免调用 Deque 的其他方法。实际上,以上都是对队首进行操作而不是队尾。
class Solution {
public String removeDuplicateLetters(String s) {
LinkedList<Character> stack = new LinkedList<>();
int[] count = new int[26];
for (char ch : s.toCharArray()) count[ch - 'a'] += 1;
for (char ch : s.toCharArray()) {
if (stack.contains(ch)) {
count[ch - 'a'] -= 1;
continue;
}
while (!stack.isEmpty() && stack.peek() > ch && count[stack.peek() - 'a'] > 1) {
count[stack.pop() - 'a'] -= 1;
}
stack.push(ch);
}
StringBuilder res = new StringBuilder();
while (!stack.isEmpty()) res.append(stack.removeLast());
return res.toString();
}
}
Stack 的作用
JVM 在处理 Java 方法调用的时候就会通过栈这种数据结构维护方法调用的层次。JVM 会创建方法调用栈,每调用一个方法时,先将参数压栈,然后执行对应的方法;当方法返回时,返回值压栈,调用方法通过出栈操作获得方法返回值。
4.3 Queue 实现类#
- LinkedList:可以用它来实现双向队列。
- PriorityQueue:基于堆结构实现,可以用它来实现优先队列。
1. LinkedList
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
// Pointer to first node.
transient Node<E> first;
// Pointer to last node.
transient Node<E> last;
...
LinkedList 中的节点定义如下:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
2. PriorityQueue
PriorityQueue 中堆结构默认是最小堆,如需实现最大堆,覆写 compare() 即可。父子节点的编号之间有如下关系:
- leftNo = parentNo * 2 + 1
- rightNo = parentNo * 2 + 2
- parentNo = (nodeNo - 1) / 2
常见的 topK 问题使用最小堆来解决,相反的求最小的若干数则用最大堆。