Spring Framework
“From configuration to security, web apps to big data—whatever the infrastructure needs of your application may be, there is a Spring Project to help you build it. Start small and use just what you need—Spring is modular by design.”
Spring 是一个生态体系,也可以说是技术体系,是集大成者,它包含了 Spring Framework、Spring Boot、Spring Cloud等。平时常说的 Spring 其实是指 Spring Framework,它是整个 Spring 生态的基石。
一、Spring Framework#
“Provides core support for dependency injection, transaction management, web apps, data access, messaging, and more. Spring focuses on the “plumbing” of enterprise applications so that teams can focus on application-level business logic, without unnecessary ties to specific deployment environments.”
Spring Framework 专注于企业级应用程序的 plumbing,以便开发团队可以专注于应用程序的业务逻辑。这里的 plumbing 指的就是为依赖注入、事务管理、WEB 应用、数据访问等提供了核心的支持。
Spring Framework 主要具有以下特点:
- 核心技术 :依赖注入 DI,面向切面 AOP,事件 events;
- 测试 :模拟对象,TestContext 框架,Spring MVC 测试;
- 数据访问 :事务,DAO 支持,JDBC,ORM,编组 XML;
- Web 支持 : Spring MVC 和 Spring WebFlux Web 框架。
二、IoC & DI#
下图是传统的程序设计,对象的创建都由客户端来完成,如果一个系统有大量的组件,其生命周期和相互之间的依赖关系都由组件自身来维护,不但大大增加了系统的复杂度,而且会导致组件之间极为紧密的耦合,继而给测试和维护带来了极大的困难,解决这个问题的关键就是 IoC。

控制反转(Inverse of Control,IoC)是一种设计思想,是将原本在程序中手动创建对象的控制权,交由 Spring 框架来管理。 IoC 在其他语言中也有应用,并非 Spirng 特有。IoC 主要的实现方式有两种:依赖查找和依赖注入,依赖注入是更可取的方式 [2]。Martin Fowler 认为 IoC 应改名为 DI:IoC 太普遍了,应当用更加准确的定义 DI 来指代它。
依赖注入(Dependency Injection,DI)指组件之间依赖关系由容器在运行期决定,即由容器动态的将某个依赖关系注入到组件之中。依赖注入的目的并非为软件系统带来更多功能,而是为了提升组件重用的频率,并为系统搭建一个灵活、可扩展的平台。通过依赖注入机制,我们只需要通过简单的配置,而无需任何代码就可指定目标需要的资源,完成自身的业务逻辑,而不需要关心具体的资源来自何处,由谁实现。
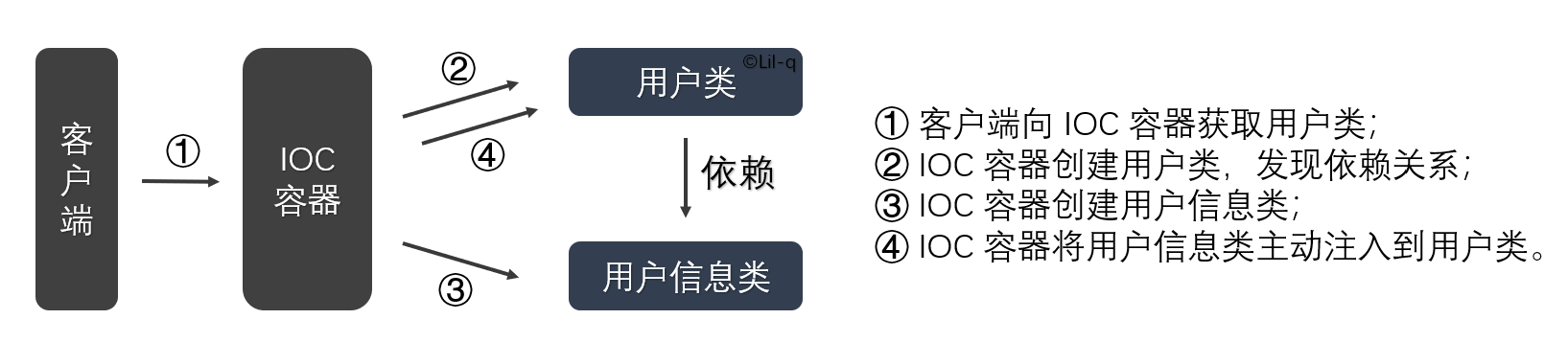
IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件或注解即可,完全不用考虑对象是如何被创建出来的。
IoC 的思想最核心的地方在于,资源不是由使用资源的双方来管理,而是由不使用资源的第三方来管理 [3] ,这样做带来的好处主要有:
- 资源集中管理,实现资源的可配置和易管理;
- 降低了使用资源双方的依赖程度,即解耦。
2.1 Bean#
Bean 就是 IoC 容器负责管理的对象,有如下规范:
- 所有属性为 private;
- 提供默认构造方法;
- 提供 getter 和 setter;
- 实现 serializable 接口。
当在 Spring 中定义一个 Bean 时,必须声明该 Bean 的作用域的选项。Spring 框架支持以下五个作用域,后三个只在 web-aware Spring ApplicationContext 的上下文中有效。
| 作用域 | 描述 |
|---|---|
| singleton | 单例(默认) |
| prototype | 每次请求都会创建一个新的 Bean 实例 |
| request | 每一次 HTTP 请求产生一个新的 Bean,仅当前 HTTP request 有效 |
| session | 每一次 HTTP 请求产生一个新的 Bean,仅当前 HTTP session 有效 |
| global-session | 全局session作用域 |
单例 Bean 存在线程问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。
常见的有两种解决办法:
- 在 Bean 对象中尽量避免定义可变的成员变量(不太现实);
- 在类中定义一个 ThreadLocal 成员变量,将需要的可变成员变量保存在 ThreadLocal 中(推荐的一种方式)。
2.2 Bean 的生命周期#
我们一般使用 @Autowired 注解自动装配 Bean,要想把类标识成可用于 @Autowired 注解自动装配的 Bean 的类,采用以下注解可实现:
@Component:通用的注解,可标注任意类为 Spring 组件;@Repository: 对应持久层即 Dao 层,主要用于数据库相关操作;@Service: 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层;@Controller: 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
Bean 的生命周期概括起来就是 4 个阶段:
- 实例化(Instantiation)
- 属性填充(Populate)
- 初始化(Initialization)
- 销毁(Destruction)
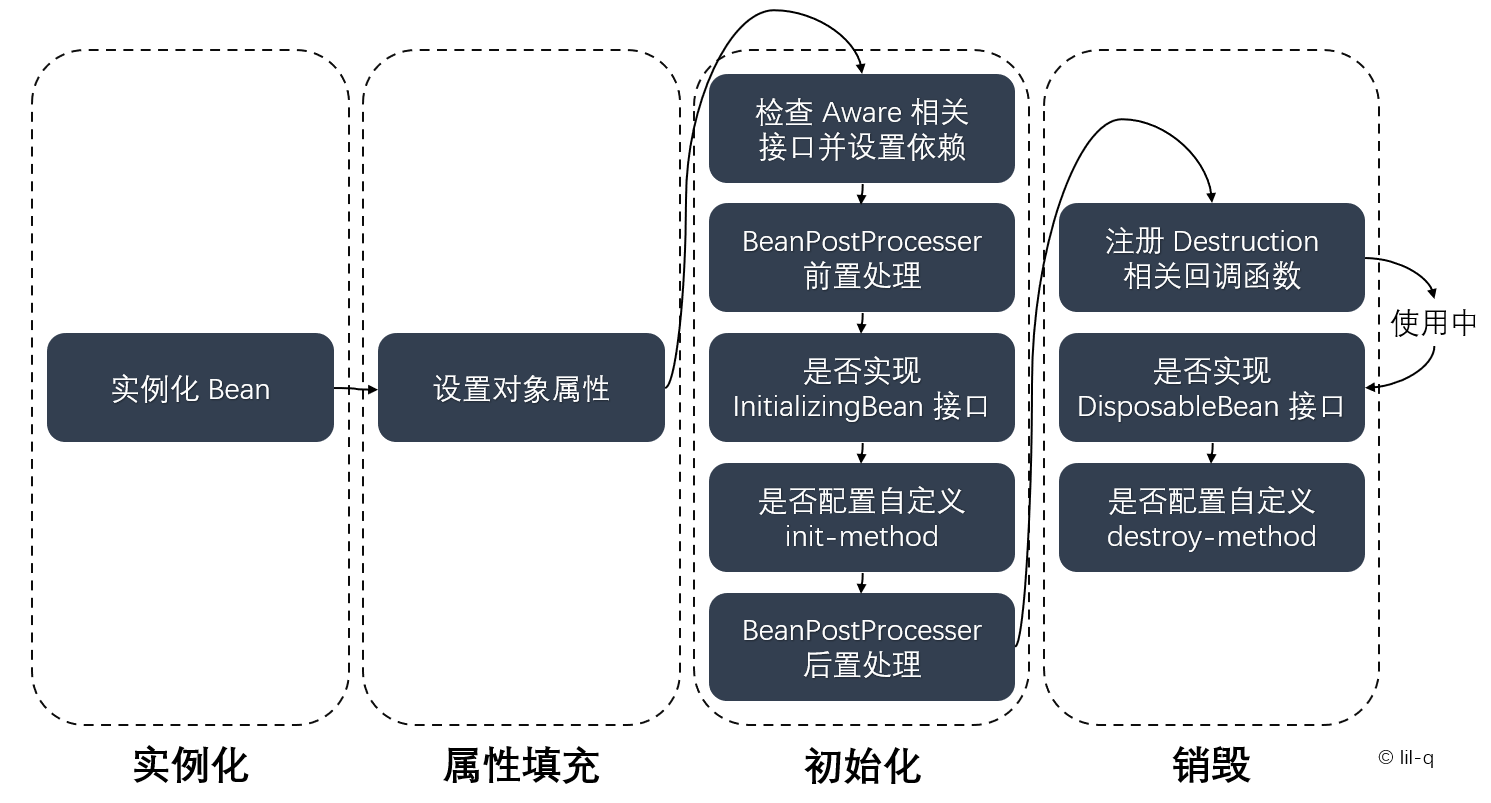
Spring 当中提供了两种实例化方案: BeanUtils 和 Cglib 方式。BeanUtils 实现机制是通过 Java 的反射机制,Cglib 是一个第三方类库采用的是一种字节码加强方式机制。 Spring 中采用的默认实例化策略是 Cglib。
2.3 循环依赖问题#
Bean 经过实例化 、属性填充和初始化这三个过程后,在框架内部被抽象封装成 BeanDefinition 这种类型,最终所有的 BeanDefinition 交由 BeanFactory 当中的 definitionMap 统一管理起来。但这只是理想情况,如果出现循环依赖,如不采取合理的措施 Bean 将永远无法初始化。
设 A 和 B 是两个 Bean,其中 A 依赖了 B,获取 A 时就需要把 B 注入进来,要注入 B 得先获取 B,如果 B 中又有对 A 的依赖,这就会形成循环往复的相互注入,也称循环依赖问题。
Spring 中使用了三个 Map 作为缓存以解决这个问题:
| 缓存 | 用途 |
|---|---|
| singletonObjects | 存放完全初始化的 Bean,该缓存中的 Bean 可以直接使用 |
| earlySingletonObjects | 存放原始的 Bean 对象(尚未填充属性),用于解决循环依赖 |
| singletonFactories | 存放 Bean 工厂对象,用于解决循环依赖 |
简单的来说就是在实例化和属性赋值之间加入了暴露单例工厂的过程,即把单例工厂加入到 singletonFactories 缓存中。如果出现循环依赖,在第二次需要创建 A 时找到第一次加入 singletonFactories 缓存的单例工厂并调用 getObject() 获取早期引用并将其加入 earlySingletonObjects 来提前跳出循环,之后再出现循环创建 A,则直接从 earlySingletonObjects 缓存中获取早期引用即可,具体步骤如下:
- 实例化 A;
- 暴露单例工厂,将其加入到 singletonFactories;
- 解析依赖,A 解析到 B,B 又解析到 A;
- 不再对 A 进行完整的创建过程,否则会陷入循环依赖,具体分支如下:
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
Object singletonObject = this.singletonObjects.get(beanName);
// 没有完全初始化好的这个 bean 并且这个 bean 正在初始化中
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
// 从缓存中获取早期引用,如果获取到了说明之前已经出现了循环依赖
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 能够获取单例工厂,说明是第一次出现循环依赖
singletonObject = singletonFactory.getObject();
// 加入到早期引用 Map,之后都从这里找
this.earlySingletonObjects.put(beanName, singletonObject);
// 删去单例工厂 Map 中的 key,之后不会再用到了
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
为什么同时需要 earlySingletonObjects 和 singletonFactories 两个缓存来解决循环依赖问题呢?
其实这是为了兼顾到 AOP,对于普通对象,确实只要返回刚创建完的早期引用就好了,但对于内部有被 AOP 增强的方法的对象,需要返回的是代理对象。可以看到 ObjectFactory 匿名内部类里面调用的 getEarlyBeanReference() 方法如下:
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
// SmartInstantiationAwareBeanPostProcessor 这个后置处理器会在返回早期对象时被调用,如果返回的对象需要加强,那这里就会生成代理对象
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
}
}
}
return exposedObject;
}
对于一般的对象,返回的就是传入的早期对象,但是对于内部有被 AOP 增强的方法的对象,会使用后置处理器返回一个代理对象。如果在解决循环依赖时生成了代理对象,那么 AbstractAutoProxyCreator 会把原对象放入一个 Map 中,这个 Map 的作用是防止同类对象被重复动态代理。
2.4 BeanFactory#
BeanFactory 和 ApplicationContext 的区别在于,BeanFactory 的实现是按需创建,即第一次获取 Bean 时才创建这个 Bean,而 ApplicationContext 会一次性创建所有的 Bean。实际上,ApplicationContext 接口是从 BeanFactory 接口继承而来的,并且,ApplicationContext 提供了一些额外的功能,包括国际化支持、事件和通知机制等。通常情况下,我们总是使用 ApplicationContext,很少会考虑使用 BeanFactory。
2.5 Autowired#
@Autowired 是属于 Spring 的注解,默认按类型装配(byType)。在启动 spring IoC 时,容器自动装载了一个 AutowiredAnnotationBeanPostProcessor 后置处理器,当容器扫描到 @Autowied、@Resource 或 @Inject 时,就会在 IoC 容器自动查找需要的 Bean,并装配给该对象的属性。在使用 @Autowired 时,首先在容器中查询对应类型的 Bean:
- 如果查询结果刚好为一个,就将该 Bean 装配给
@Autowired指定的数据; - 如果查询的结果不止一个,那么
@Autowired会根据名称来查找; - 如果上述查找的结果为空,那么会抛出异常。解决方法时,使用
required=false。
@Resource 注解是属于 JDK 的注解,默认按名称装配(byName)。名称可以通过 @Resource 的 name 属性指定,如果没有指定 name 属性,当注解标注在字段上,即默认取字段的名称作为 Bean 名称寻找依赖对象,当注解标注在属性的 setter 方法上,即默认取属性名作为 Bean 名称寻找依赖对象。
三、AOP#
面向切面编程(Aspect-Oriented Programming,AOP)能够将那些与业务无关,却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可拓展性和可维护性。
Spring AOP 就是基于动态代理的,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 JDK Proxy 去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 Cglib 生成一个被代理对象的子类来作为代理。
比如对于 Blog 系统,登录前需要验证身份,这就需要 Spring Boot 中的 Interceptor,其原理就是 AOP。
3.1 AspectJ#
1. Capabilities and Goals
Spring AOP 旨在通过 Spring IoC 提供一个简单的 AOP 实现,它只能用于 Spring 容器管理的 Bean。
AspectJ 是最原始的 AOP 实现技术,更为健壮,能够被应用于所有的领域对象。
2. Weaving
AspectJ and Spring AOP使用了不同的织入方式,这影响了他们在性能和易用性方面的行为。AspectJ 使用了三种不同类型的织入:
- 编译时织入:AspectJ 编译器同时加载我们切面的源代码和我们的应用程序,并生成一个织入后的类文件作为输出。
- 编译后织入:这就是所熟悉的二进制织入。它被用来编织现有的类文件和 JAR 文件与我们的切面。
- 加载时织入:这和之前的二进制编织完全一样,所不同的是织入会被延后,直到类加载器将类加载到 JVM。
AspectJ 使用的是编译期和类加载时进行织入,Spring AOP 利用的是运行时织入。
3. Performance
考虑到性能问题,编译时织入比运行时织入快很多。Spring AOP 是基于代理的框架,因此应用运行时会有目标类的代理对象生成。另外,每个切面还有一些方法调用,这会对性能造成影响。
AspectJ 不同于 Spring AOP,是在应用执行前织入切面到代码中,没有额外的运行时开销。由于以上原因,AspectJ 经过测试大概 8 到 35 倍快于 Spring AOP。
3.2 事务#
- 编程式事务(不推荐使用),在代码中硬编码;
- 声明式事务(推荐使用),在配置文件中配置,基于 AOP,将具体业务逻辑与事务处理解耦。
声明式事务又分为两种:
- 基于 XML 的声明式事务;
- 基于注解的声明式事务。
TransactionDefinition 接口中定义了五个表示隔离级别的常量,其实和数据库是一致的:
-
TransactionDefinition.ISOLATION_DEFAULT:
使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别。
-
TransactionDefinition.ISOLATION_READ_UNCOMMITTED:
最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。
-
TransactionDefinition.ISOLATION_READ_COMMITTED:
允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生。
-
TransactionDefinition.ISOLATION_REPEATABLE_READ:
对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
-
TransactionDefinition.ISOLATION_SERIALIZABLE:
最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
参考#
- 故事开始的地方——Spring
- 《EXPERT ONE ON ONE J2EE DEVELOPMENT WITHOUT EJB》
- IoC的优势
- Bean 生命周期
- 依赖注入实现原理
- Spring IOC 容器源码分析 - 循环依赖的解决办法
- 为什么是三级缓存